Logging
Log Proxy input, output, and exceptions using:
- Langfuse
- OpenTelemetry
- Custom Callbacks
- Langsmith
- DataDog
- DynamoDB
- etc.
Getting the LiteLLM Call ID
LiteLLM generates a unique call_id for each request. This call_id can be
used to track the request across the system. This can be very useful for finding
the info for a particular request in a logging system like one of the systems
mentioned in this page.
curl -i -sSL --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "what llm are you"}]
}' | grep 'x-litellm'
The output of this is:
x-litellm-call-id: b980db26-9512-45cc-b1da-c511a363b83f
x-litellm-model-id: cb41bc03f4c33d310019bae8c5afdb1af0a8f97b36a234405a9807614988457c
x-litellm-model-api-base: https://x-example-1234.openai.azure.com
x-litellm-version: 1.40.21
x-litellm-response-cost: 2.85e-05
x-litellm-key-tpm-limit: None
x-litellm-key-rpm-limit: None
A number of these headers could be useful for troubleshooting, but the
x-litellm-call-id is the one that is most useful for tracking a request across
components in your system, including in logging tools.
Redacting UserAPIKeyInfo
Redact information about the user api key (hashed token, user_id, team id, etc.), from logs.
Currently supported for Langfuse, OpenTelemetry, Logfire, ArizeAI logging.
litellm_settings:
callbacks: ["langfuse"]
redact_user_api_key_info: true
Removes any field with user_api_key_* from metadata.
What gets logged? StandardLoggingPayload
Found under kwargs["standard_logging_object"]. This is a standard payload, logged for every response.
class StandardLoggingPayload(TypedDict):
id: str
call_type: str
response_cost: float
total_tokens: int
prompt_tokens: int
completion_tokens: int
startTime: float
endTime: float
completionStartTime: float
model_map_information: StandardLoggingModelInformation
model: str
model_id: Optional[str]
model_group: Optional[str]
api_base: str
metadata: StandardLoggingMetadata
cache_hit: Optional[bool]
cache_key: Optional[str]
saved_cache_cost: Optional[float]
request_tags: list
end_user: Optional[str]
requester_ip_address: Optional[str] # IP address of requester
requester_metadata: Optional[dict] # metadata passed in request in the "metadata" field
messages: Optional[Union[str, list, dict]]
response: Optional[Union[str, list, dict]]
model_parameters: dict
hidden_params: StandardLoggingHiddenParams
class StandardLoggingHiddenParams(TypedDict):
model_id: Optional[str]
cache_key: Optional[str]
api_base: Optional[str]
response_cost: Optional[str]
additional_headers: Optional[dict]
class StandardLoggingModelInformation(TypedDict):
model_map_key: str
model_map_value: Optional[ModelInfo]
Logging Proxy Input/Output - Langfuse
We will use the --config to set litellm.success_callback = ["langfuse"] this will log all successfull LLM calls to langfuse. Make sure to set LANGFUSE_PUBLIC_KEY and LANGFUSE_SECRET_KEY in your environment
Step 1 Install langfuse
pip install langfuse>=2.0.0
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["langfuse"]
Step 3: Set required env variables for logging to langfuse
export LANGFUSE_PUBLIC_KEY="pk_kk"
export LANGFUSE_SECRET_KEY="sk_ss"
# Optional, defaults to https://cloud.langfuse.com
export LANGFUSE_HOST="https://xxx.langfuse.com"
Step 4: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
litellm --test
Expected output on Langfuse
Logging Metadata to Langfuse
- Curl Request
- OpenAI v1.0.0+
- Langchain
Pass metadata as part of the request body
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"metadata": {
"generation_name": "ishaan-test-generation",
"generation_id": "gen-id22",
"trace_id": "trace-id22",
"trace_user_id": "user-id2"
}
}'
Set extra_body={"metadata": { }} to metadata you want to pass
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
extra_body={
"metadata": {
"generation_name": "ishaan-generation-openai-client",
"generation_id": "openai-client-gen-id22",
"trace_id": "openai-client-trace-id22",
"trace_user_id": "openai-client-user-id2"
}
}
)
print(response)
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "gpt-3.5-turbo",
temperature=0.1,
extra_body={
"metadata": {
"generation_name": "ishaan-generation-langchain-client",
"generation_id": "langchain-client-gen-id22",
"trace_id": "langchain-client-trace-id22",
"trace_user_id": "langchain-client-user-id2"
}
}
)
messages = [
SystemMessage(
content="You are a helpful assistant that im using to make a test request to."
),
HumanMessage(
content="test from litellm. tell me why it's amazing in 1 sentence"
),
]
response = chat(messages)
print(response)
Team based Logging to Langfuse
👉 Tutorial - Allow each team to use their own Langfuse Project / custom callbacks
Redacting Messages, Response Content from Langfuse Logging
Set litellm.turn_off_message_logging=True This will prevent the messages and responses from being logged to langfuse, but request metadata will still be logged.
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["langfuse"]
turn_off_message_logging: True
If you have this feature turned on, you can override it for specific requests by
setting a request header LiteLLM-Disable-Message-Redaction: true.
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'LiteLLM-Disable-Message-Redaction: true' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
LiteLLM-specific Tags on Langfuse - cache_hit, cache_key
Use this if you want to control which LiteLLM-specific fields are logged as tags by the LiteLLM proxy. By default LiteLLM Proxy logs no LiteLLM-specific fields
| LiteLLM specific field | Description | Example Value |
|---|---|---|
cache_hit | Indicates whether a cache hit occured (True) or not (False) | true, false |
cache_key | The Cache key used for this request | d2b758c**** |
proxy_base_url | The base URL for the proxy server, the value of env var PROXY_BASE_URL on your server | https://proxy.example.com |
user_api_key_alias | An alias for the LiteLLM Virtual Key. | prod-app1 |
user_api_key_user_id | The unique ID associated with a user's API key. | user_123, user_456 |
user_api_key_user_email | The email associated with a user's API key. | user@example.com, admin@example.com |
user_api_key_team_alias | An alias for a team associated with an API key. | team_alpha, dev_team |
Usage
Specify langfuse_default_tags to control what litellm fields get logged on Langfuse
Example config.yaml
model_list:
- model_name: gpt-4
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
success_callback: ["langfuse"]
# 👇 Key Change
langfuse_default_tags: ["cache_hit", "cache_key", "proxy_base_url", "user_api_key_alias", "user_api_key_user_id", "user_api_key_user_email", "user_api_key_team_alias", "semantic-similarity", "proxy_base_url"]
🔧 Debugging - Viewing RAW CURL sent from LiteLLM to provider
Use this when you want to view the RAW curl request sent from LiteLLM to the LLM API
- Curl Request
- OpenAI v1.0.0+
- Langchain
Pass metadata as part of the request body
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"metadata": {
"log_raw_request": true
}
}'
Set extra_body={"metadata": {"log_raw_request": True }} to metadata you want to pass
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
extra_body={
"metadata": {
"log_raw_request": True
}
}
)
print(response)
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "gpt-3.5-turbo",
temperature=0.1,
extra_body={
"metadata": {
"log_raw_request": True
}
}
)
messages = [
SystemMessage(
content="You are a helpful assistant that im using to make a test request to."
),
HumanMessage(
content="test from litellm. tell me why it's amazing in 1 sentence"
),
]
response = chat(messages)
print(response)
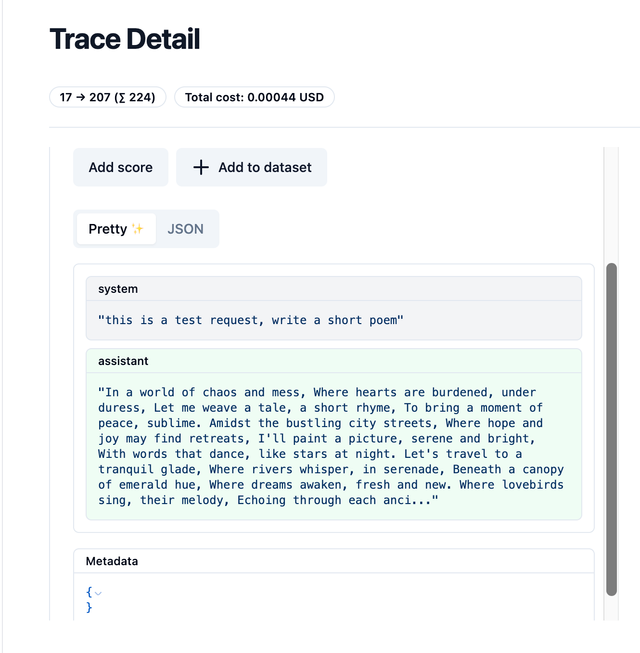
Expected Output on Langfuse
You will see raw_request in your Langfuse Metadata. This is the RAW CURL command sent from LiteLLM to your LLM API provider
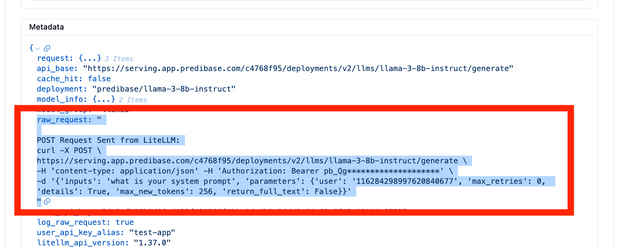
Logging Proxy Input/Output in OpenTelemetry format
[Optional] Customize OTEL Service Name and OTEL TRACER NAME by setting the following variables in your environment
OTEL_TRACER_NAME=<your-trace-name> # default="litellm"
OTEL_SERVICE_NAME=<your-service-name>` # default="litellm"
- Log to console
- Log to Honeycomb
- Log to Traceloop Cloud
- Log to OTEL HTTP Collector
- Log to OTEL GRPC Collector
Step 1: Set callbacks and env vars
Add the following to your env
OTEL_EXPORTER="console"
Add otel as a callback on your litellm_config.yaml
litellm_settings:
callbacks: ["otel"]
Step 2: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --detailed_debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Step 3: Expect to see the following logged on your server logs / console
This is the Span from OTEL Logging
{
"name": "litellm-acompletion",
"context": {
"trace_id": "0x8d354e2346060032703637a0843b20a3",
"span_id": "0xd8d3476a2eb12724",
"trace_state": "[]"
},
"kind": "SpanKind.INTERNAL",
"parent_id": null,
"start_time": "2024-06-04T19:46:56.415888Z",
"end_time": "2024-06-04T19:46:56.790278Z",
"status": {
"status_code": "OK"
},
"attributes": {
"model": "llama3-8b-8192"
},
"events": [],
"links": [],
"resource": {
"attributes": {
"service.name": "litellm"
},
"schema_url": ""
}
}
Quick Start - Log to Honeycomb
Step 1: Set callbacks and env vars
Add the following to your env
OTEL_EXPORTER="otlp_http"
OTEL_ENDPOINT="https://api.honeycomb.io/v1/traces"
OTEL_HEADERS="x-honeycomb-team=<your-api-key>"
Add otel as a callback on your litellm_config.yaml
litellm_settings:
callbacks: ["otel"]
Step 2: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --detailed_debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Quick Start - Log to Traceloop
Step 1: Add the following to your env
OTEL_EXPORTER="otlp_http"
OTEL_ENDPOINT="https://api.traceloop.com"
OTEL_HEADERS="Authorization=Bearer%20<your-api-key>"
Step 2: Add otel as a callbacks
litellm_settings:
callbacks: ["otel"]
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --detailed_debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Quick Start - Log to OTEL Collector
Step 1: Set callbacks and env vars
Add the following to your env
OTEL_EXPORTER="otlp_http"
OTEL_ENDPOINT="http:/0.0.0.0:4317"
OTEL_HEADERS="x-honeycomb-team=<your-api-key>" # Optional
Add otel as a callback on your litellm_config.yaml
litellm_settings:
callbacks: ["otel"]
Step 2: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --detailed_debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Quick Start - Log to OTEL GRPC Collector
Step 1: Set callbacks and env vars
Add the following to your env
OTEL_EXPORTER="otlp_grpc"
OTEL_ENDPOINT="http:/0.0.0.0:4317"
OTEL_HEADERS="x-honeycomb-team=<your-api-key>" # Optional
Add otel as a callback on your litellm_config.yaml
litellm_settings:
callbacks: ["otel"]
Step 2: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --detailed_debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
🎉 Expect to see this trace logged in your OTEL collector
Redacting Messages, Response Content from OTEL Logging
Set message_logging=False for otel, no messages / response will be logged
litellm_settings:
callbacks: ["otel"]
## 👇 Key Change
callback_settings:
otel:
message_logging: False
Context propagation across Services Traceparent HTTP Header
❓ Use this when you want to pass information about the incoming request in a distributed tracing system
✅ Key change: Pass the traceparent header in your requests. Read more about traceparent headers here
traceparent: 00-80e1afed08e019fc1110464cfa66635c-7a085853722dc6d2-01
Example Usage
- Make Request to LiteLLM Proxy with
traceparentheader
import openai
import uuid
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
example_traceparent = f"00-80e1afed08e019fc1110464cfa66635c-02e80198930058d4-01"
extra_headers = {
"traceparent": example_traceparent
}
_trace_id = example_traceparent.split("-")[1]
print("EXTRA HEADERS: ", extra_headers)
print("Trace ID: ", _trace_id)
response = client.chat.completions.create(
model="llama3",
messages=[
{"role": "user", "content": "this is a test request, write a short poem"}
],
extra_headers=extra_headers,
)
print(response)
# EXTRA HEADERS: {'traceparent': '00-80e1afed08e019fc1110464cfa66635c-02e80198930058d4-01'}
# Trace ID: 80e1afed08e019fc1110464cfa66635c
- Lookup Trace ID on OTEL Logger
Search for Trace=80e1afed08e019fc1110464cfa66635c on your OTEL Collector

Forwarding Traceparent HTTP Header to LLM APIs
Use this if you want to forward the traceparent headers to your self hosted LLMs like vLLM
Set forward_traceparent_to_llm_provider: True in your config.yaml. This will forward the traceparent header to your LLM API
Only use this for self hosted LLMs, this can cause Bedrock, VertexAI calls to fail
litellm_settings:
forward_traceparent_to_llm_provider: True
Custom Callback Class [Async]
Use this when you want to run custom callbacks in python
Step 1 - Create your custom litellm callback class
We use litellm.integrations.custom_logger for this, more details about litellm custom callbacks here
Define your custom callback class in a python file.
Here's an example custom logger for tracking key, user, model, prompt, response, tokens, cost. We create a file called custom_callbacks.py and initialize proxy_handler_instance
from litellm.integrations.custom_logger import CustomLogger
import litellm
# This file includes the custom callbacks for LiteLLM Proxy
# Once defined, these can be passed in proxy_config.yaml
class MyCustomHandler(CustomLogger):
def log_pre_api_call(self, model, messages, kwargs):
print(f"Pre-API Call")
def log_post_api_call(self, kwargs, response_obj, start_time, end_time):
print(f"Post-API Call")
def log_stream_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Stream")
def log_success_event(self, kwargs, response_obj, start_time, end_time):
print("On Success")
def log_failure_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Failure")
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
# log: key, user, model, prompt, response, tokens, cost
# Access kwargs passed to litellm.completion()
model = kwargs.get("model", None)
messages = kwargs.get("messages", None)
user = kwargs.get("user", None)
# Access litellm_params passed to litellm.completion(), example access `metadata`
litellm_params = kwargs.get("litellm_params", {})
metadata = litellm_params.get("metadata", {}) # headers passed to LiteLLM proxy, can be found here
# Calculate cost using litellm.completion_cost()
cost = litellm.completion_cost(completion_response=response_obj)
response = response_obj
# tokens used in response
usage = response_obj["usage"]
print(
f"""
Model: {model},
Messages: {messages},
User: {user},
Usage: {usage},
Cost: {cost},
Response: {response}
Proxy Metadata: {metadata}
"""
)
return
async def async_log_failure_event(self, kwargs, response_obj, start_time, end_time):
try:
print(f"On Async Failure !")
print("\nkwargs", kwargs)
# Access kwargs passed to litellm.completion()
model = kwargs.get("model", None)
messages = kwargs.get("messages", None)
user = kwargs.get("user", None)
# Access litellm_params passed to litellm.completion(), example access `metadata`
litellm_params = kwargs.get("litellm_params", {})
metadata = litellm_params.get("metadata", {}) # headers passed to LiteLLM proxy, can be found here
# Acess Exceptions & Traceback
exception_event = kwargs.get("exception", None)
traceback_event = kwargs.get("traceback_exception", None)
# Calculate cost using litellm.completion_cost()
cost = litellm.completion_cost(completion_response=response_obj)
print("now checking response obj")
print(
f"""
Model: {model},
Messages: {messages},
User: {user},
Cost: {cost},
Response: {response_obj}
Proxy Metadata: {metadata}
Exception: {exception_event}
Traceback: {traceback_event}
"""
)
except Exception as e:
print(f"Exception: {e}")
proxy_handler_instance = MyCustomHandler()
# Set litellm.callbacks = [proxy_handler_instance] on the proxy
# need to set litellm.callbacks = [proxy_handler_instance] # on the proxy
Step 2 - Pass your custom callback class in config.yaml
We pass the custom callback class defined in Step1 to the config.yaml.
Set callbacks to python_filename.logger_instance_name
In the config below, we pass
- python_filename:
custom_callbacks.py - logger_instance_name:
proxy_handler_instance. This is defined in Step 1
callbacks: custom_callbacks.proxy_handler_instance
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance # sets litellm.callbacks = [proxy_handler_instance]
Step 3 - Start proxy + test request
litellm --config proxy_config.yaml
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "good morning good sir"
}
],
"user": "ishaan-app",
"temperature": 0.2
}'
Resulting Log on Proxy
On Success
Model: gpt-3.5-turbo,
Messages: [{'role': 'user', 'content': 'good morning good sir'}],
User: ishaan-app,
Usage: {'completion_tokens': 10, 'prompt_tokens': 11, 'total_tokens': 21},
Cost: 3.65e-05,
Response: {'id': 'chatcmpl-8S8avKJ1aVBg941y5xzGMSKrYCMvN', 'choices': [{'finish_reason': 'stop', 'index': 0, 'message': {'content': 'Good morning! How can I assist you today?', 'role': 'assistant'}}], 'created': 1701716913, 'model': 'gpt-3.5-turbo-0613', 'object': 'chat.completion', 'system_fingerprint': None, 'usage': {'completion_tokens': 10, 'prompt_tokens': 11, 'total_tokens': 21}}
Proxy Metadata: {'user_api_key': None, 'headers': Headers({'host': '0.0.0.0:4000', 'user-agent': 'curl/7.88.1', 'accept': '*/*', 'authorization': 'Bearer sk-1234', 'content-length': '199', 'content-type': 'application/x-www-form-urlencoded'}), 'model_group': 'gpt-3.5-turbo', 'deployment': 'gpt-3.5-turbo-ModelID-gpt-3.5-turbo'}
Logging Proxy Request Object, Header, Url
Here's how you can access the url, headers, request body sent to the proxy for each request
class MyCustomHandler(CustomLogger):
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
litellm_params = kwargs.get("litellm_params", None)
proxy_server_request = litellm_params.get("proxy_server_request")
print(proxy_server_request)
Expected Output
{
"url": "http://testserver/chat/completions",
"method": "POST",
"headers": {
"host": "testserver",
"accept": "*/*",
"accept-encoding": "gzip, deflate",
"connection": "keep-alive",
"user-agent": "testclient",
"authorization": "Bearer None",
"content-length": "105",
"content-type": "application/json"
},
"body": {
"model": "Azure OpenAI GPT-4 Canada",
"messages": [
{
"role": "user",
"content": "hi"
}
],
"max_tokens": 10
}
}
Logging model_info set in config.yaml
Here is how to log the model_info set in your proxy config.yaml. Information on setting model_info on config.yaml
class MyCustomHandler(CustomLogger):
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
litellm_params = kwargs.get("litellm_params", None)
model_info = litellm_params.get("model_info")
print(model_info)
Expected Output
{'mode': 'embedding', 'input_cost_per_token': 0.002}
Logging responses from proxy
Both /chat/completions and /embeddings responses are available as response_obj
Note: for /chat/completions, both stream=True and non stream responses are available as response_obj
class MyCustomHandler(CustomLogger):
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
print(response_obj)
Expected Output /chat/completion [for both stream and non-stream responses]
ModelResponse(
id='chatcmpl-8Tfu8GoMElwOZuj2JlHBhNHG01PPo',
choices=[
Choices(
finish_reason='stop',
index=0,
message=Message(
content='As an AI language model, I do not have a physical body and therefore do not possess any degree or educational qualifications. My knowledge and abilities come from the programming and algorithms that have been developed by my creators.',
role='assistant'
)
)
],
created=1702083284,
model='chatgpt-v-2',
object='chat.completion',
system_fingerprint=None,
usage=Usage(
completion_tokens=42,
prompt_tokens=5,
total_tokens=47
)
)
Expected Output /embeddings
{
'model': 'ada',
'data': [
{
'embedding': [
-0.035126980394124985, -0.020624293014407158, -0.015343423001468182,
-0.03980357199907303, -0.02750781551003456, 0.02111034281551838,
-0.022069307044148445, -0.019442008808255196, -0.00955679826438427,
-0.013143060728907585, 0.029583381488919258, -0.004725852981209755,
-0.015198921784758568, -0.014069183729588985, 0.00897879246622324,
0.01521205808967352,
# ... (truncated for brevity)
]
}
]
}
Custom Callback APIs [Async]
This is an Enterprise only feature Get Started with Enterprise here
Use this if you:
- Want to use custom callbacks written in a non Python programming language
- Want your callbacks to run on a different microservice
Step 1. Create your generic logging API endpoint
Set up a generic API endpoint that can receive data in JSON format. The data will be included within a "data" field.
Your server should support the following Request format:
curl --location https://your-domain.com/log-event \
--request POST \
--header "Content-Type: application/json" \
--data '{
"data": {
"id": "chatcmpl-8sgE89cEQ4q9biRtxMvDfQU1O82PT",
"call_type": "acompletion",
"cache_hit": "None",
"startTime": "2024-02-15 16:18:44.336280",
"endTime": "2024-02-15 16:18:45.045539",
"model": "gpt-3.5-turbo",
"user": "ishaan-2",
"modelParameters": "{'temperature': 0.7, 'max_tokens': 10, 'user': 'ishaan-2', 'extra_body': {}}",
"messages": "[{'role': 'user', 'content': 'This is a test'}]",
"response": "ModelResponse(id='chatcmpl-8sgE89cEQ4q9biRtxMvDfQU1O82PT', choices=[Choices(finish_reason='length', index=0, message=Message(content='Great! How can I assist you with this test', role='assistant'))], created=1708042724, model='gpt-3.5-turbo-0613', object='chat.completion', system_fingerprint=None, usage=Usage(completion_tokens=10, prompt_tokens=11, total_tokens=21))",
"usage": "Usage(completion_tokens=10, prompt_tokens=11, total_tokens=21)",
"metadata": "{}",
"cost": "3.65e-05"
}
}'
Reference FastAPI Python Server
Here's a reference FastAPI Server that is compatible with LiteLLM Proxy:
# this is an example endpoint to receive data from litellm
from fastapi import FastAPI, HTTPException, Request
app = FastAPI()
@app.post("/log-event")
async def log_event(request: Request):
try:
print("Received /log-event request")
# Assuming the incoming request has JSON data
data = await request.json()
print("Received request data:")
print(data)
# Your additional logic can go here
# For now, just printing the received data
return {"message": "Request received successfully"}
except Exception as e:
print(f"Error processing request: {str(e)}")
import traceback
traceback.print_exc()
raise HTTPException(status_code=500, detail="Internal Server Error")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="127.0.0.1", port=4000)
Step 2. Set your GENERIC_LOGGER_ENDPOINT to the endpoint + route we should send callback logs to
os.environ["GENERIC_LOGGER_ENDPOINT"] = "http://localhost:4000/log-event"
Step 3. Create a config.yaml file and set litellm_settings: success_callback = ["generic"]
Example litellm proxy config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["generic"]
Start the LiteLLM Proxy and make a test request to verify the logs reached your callback API
Logging LLM IO to Langsmith
- Set
success_callback: ["langsmith"]on litellm config.yaml
If you're using a custom LangSmith instance, you can set the
LANGSMITH_BASE_URL environment variable to point to your instance.
litellm_settings:
success_callback: ["langsmith"]
environment_variables:
LANGSMITH_API_KEY: "lsv2_pt_xxxxxxxx"
LANGSMITH_PROJECT: "litellm-proxy"
LANGSMITH_BASE_URL: "https://api.smith.langchain.com" # (Optional - only needed if you have a custom Langsmith instance)
- Start Proxy
litellm --config /path/to/config.yaml
- Test it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "Hello, Claude gm!"
}
],
}
'
Expect to see your log on Langfuse
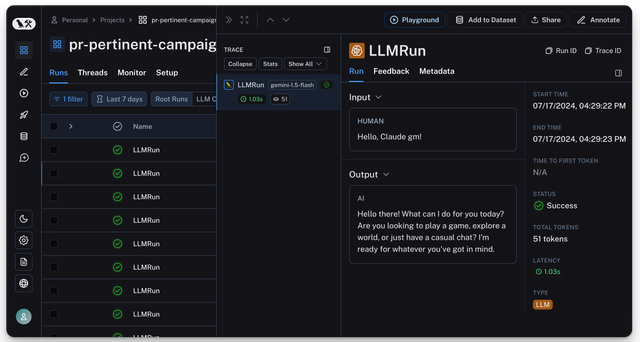
Logging LLM IO to Arize AI
- Set
success_callback: ["arize"]on litellm config.yaml
model_list:
- model_name: gpt-4
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
callbacks: ["arize"]
environment_variables:
ARIZE_SPACE_KEY: "d0*****"
ARIZE_API_KEY: "141a****"
ARIZE_ENDPOINT: "https://otlp.arize.com/v1" # OPTIONAL - your custom arize api endpoint
- Start Proxy
litellm --config /path/to/config.yaml
- Test it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "Hello, Claude gm!"
}
],
}
'
Expect to see your log on Langfuse
Logging LLM IO to Langtrace
- Set
success_callback: ["langtrace"]on litellm config.yaml
model_list:
- model_name: gpt-4
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
callbacks: ["langtrace"]
environment_variables:
LANGTRACE_API_KEY: "141a****"
- Start Proxy
litellm --config /path/to/config.yaml
- Test it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "Hello, Claude gm!"
}
],
}
'
Logging LLM IO to Galileo
[BETA]
Log LLM I/O on www.rungalileo.io
Beta Integration
Required Env Variables
export GALILEO_BASE_URL="" # For most users, this is the same as their console URL except with the word 'console' replaced by 'api' (e.g. http://www.console.galileo.myenterprise.com -> http://www.api.galileo.myenterprise.com)
export GALILEO_PROJECT_ID=""
export GALILEO_USERNAME=""
export GALILEO_PASSWORD=""
Quick Start
- Add to Config.yaml
model_list:
- litellm_params:
api_base: https://exampleopenaiendpoint-production.up.railway.app/
api_key: my-fake-key
model: openai/my-fake-model
model_name: fake-openai-endpoint
litellm_settings:
success_callback: ["galileo"] # 👈 KEY CHANGE
- Start Proxy
litellm --config /path/to/config.yaml
- Test it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
🎉 That's it - Expect to see your Logs on your Galileo Dashboard
Logging Proxy Cost + Usage - OpenMeter
Bill customers according to their LLM API usage with OpenMeter
Required Env Variables
# from https://openmeter.cloud
export OPENMETER_API_ENDPOINT="" # defaults to https://openmeter.cloud
export OPENMETER_API_KEY=""
Quick Start
- Add to Config.yaml
model_list:
- litellm_params:
api_base: https://openai-function-calling-workers.tasslexyz.workers.dev/
api_key: my-fake-key
model: openai/my-fake-model
model_name: fake-openai-endpoint
litellm_settings:
success_callback: ["openmeter"] # 👈 KEY CHANGE
- Start Proxy
litellm --config /path/to/config.yaml
- Test it!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
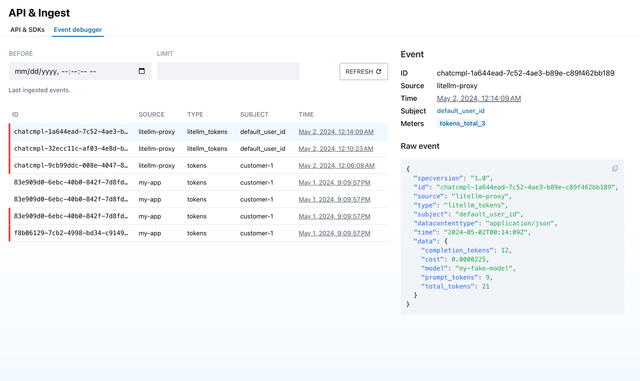
Logging Proxy Input/Output - DataDog
We will use the --config to set litellm.success_callback = ["datadog"] this will log all successfull LLM calls to DataDog
Step 1: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["datadog"] # logs llm success logs on datadog
service_callback: ["datadog"] # logs redis, postgres failures on datadog
Step 2: Set Required env variables for datadog
DD_API_KEY="5f2d0f310***********" # your datadog API Key
DD_SITE="us5.datadoghq.com" # your datadog base url
DD_SOURCE="litellm_dev" # [OPTIONAL] your datadog source. use to differentiate dev vs. prod deployments
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"metadata": {
"your-custom-metadata": "custom-field",
}
}'
Expected output on Datadog
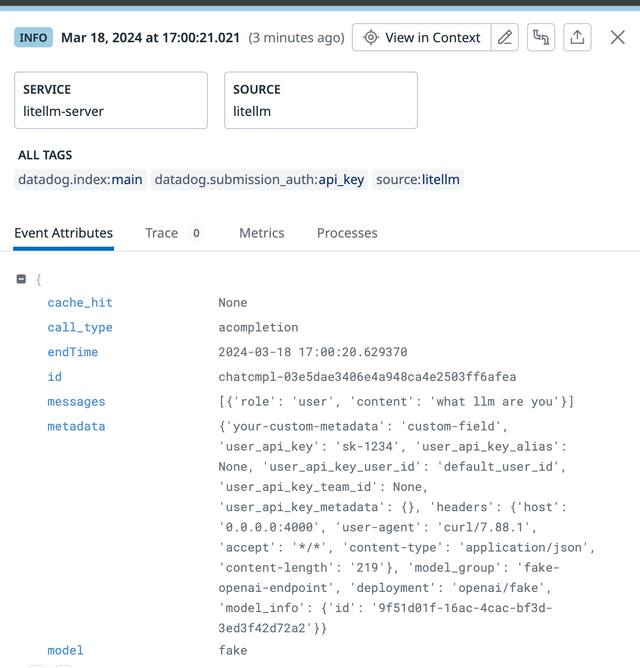
Logging Proxy Input/Output - DynamoDB
We will use the --config to set
litellm.success_callback = ["dynamodb"]litellm.dynamodb_table_name = "your-table-name"
This will log all successfull LLM calls to DynamoDB
Step 1 Set AWS Credentials in .env
AWS_ACCESS_KEY_ID = ""
AWS_SECRET_ACCESS_KEY = ""
AWS_REGION_NAME = ""
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["dynamodb"]
dynamodb_table_name: your-table-name
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "Azure OpenAI GPT-4 East",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Your logs should be available on DynamoDB
Data Logged to DynamoDB /chat/completions
{
"id": {
"S": "chatcmpl-8W15J4480a3fAQ1yQaMgtsKJAicen"
},
"call_type": {
"S": "acompletion"
},
"endTime": {
"S": "2023-12-15 17:25:58.424118"
},
"messages": {
"S": "[{'role': 'user', 'content': 'This is a test'}]"
},
"metadata": {
"S": "{}"
},
"model": {
"S": "gpt-3.5-turbo"
},
"modelParameters": {
"S": "{'temperature': 0.7, 'max_tokens': 100, 'user': 'ishaan-2'}"
},
"response": {
"S": "ModelResponse(id='chatcmpl-8W15J4480a3fAQ1yQaMgtsKJAicen', choices=[Choices(finish_reason='stop', index=0, message=Message(content='Great! What can I assist you with?', role='assistant'))], created=1702641357, model='gpt-3.5-turbo-0613', object='chat.completion', system_fingerprint=None, usage=Usage(completion_tokens=9, prompt_tokens=11, total_tokens=20))"
},
"startTime": {
"S": "2023-12-15 17:25:56.047035"
},
"usage": {
"S": "Usage(completion_tokens=9, prompt_tokens=11, total_tokens=20)"
},
"user": {
"S": "ishaan-2"
}
}
Data logged to DynamoDB /embeddings
{
"id": {
"S": "4dec8d4d-4817-472d-9fc6-c7a6153eb2ca"
},
"call_type": {
"S": "aembedding"
},
"endTime": {
"S": "2023-12-15 17:25:59.890261"
},
"messages": {
"S": "['hi']"
},
"metadata": {
"S": "{}"
},
"model": {
"S": "text-embedding-ada-002"
},
"modelParameters": {
"S": "{'user': 'ishaan-2'}"
},
"response": {
"S": "EmbeddingResponse(model='text-embedding-ada-002-v2', data=[{'embedding': [-0.03503197431564331, -0.020601635798811913, -0.015375726856291294,
}
}
Logging Proxy Input/Output - Sentry
If api calls fail (llm/database) you can log those to Sentry:
Step 1 Install Sentry
pip install --upgrade sentry-sdk
Step 2: Save your Sentry_DSN and add litellm_settings: failure_callback
export SENTRY_DSN="your-sentry-dsn"
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
# other settings
failure_callback: ["sentry"]
general_settings:
database_url: "my-bad-url" # set a fake url to trigger a sentry exception
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
litellm --test
Logging Proxy Input/Output Athina
Athina allows you to log LLM Input/Output for monitoring, analytics, and observability.
We will use the --config to set litellm.success_callback = ["athina"] this will log all successfull LLM calls to athina
Step 1 Set Athina API key
ATHINA_API_KEY = "your-athina-api-key"
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["athina"]
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "which llm are you"
}
]
}'
(BETA) Moderation with Azure Content Safety
Azure Content-Safety is a Microsoft Azure service that provides content moderation APIs to detect potential offensive, harmful, or risky content in text.
We will use the --config to set litellm.success_callback = ["azure_content_safety"] this will moderate all LLM calls using Azure Content Safety.
Step 0 Deploy Azure Content Safety
Deploy an Azure Content-Safety instance from the Azure Portal and get the endpoint and key.
Step 1 Set Athina API key
AZURE_CONTENT_SAFETY_KEY = "<your-azure-content-safety-key>"
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: ["azure_content_safety"]
azure_content_safety_params:
endpoint: "<your-azure-content-safety-endpoint>"
key: "os.environ/AZURE_CONTENT_SAFETY_KEY"
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Hi, how are you?"
}
]
}'
An HTTP 400 error will be returned if the content is detected with a value greater than the threshold set in the config.yaml.
The details of the response will describe:
- The
source: input text or llm generated text - The
category: the category of the content that triggered the moderation - The
severity: the severity from 0 to 10
Step 4: Customizing Azure Content Safety Thresholds
You can customize the thresholds for each category by setting the thresholds in the config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: ["azure_content_safety"]
azure_content_safety_params:
endpoint: "<your-azure-content-safety-endpoint>"
key: "os.environ/AZURE_CONTENT_SAFETY_KEY"
thresholds:
Hate: 6
SelfHarm: 8
Sexual: 6
Violence: 4
thresholds are not required by default, but you can tune the values to your needs.
Default values is 4 for all categories